Accelerate your business with automated document classification: 3 key benefits for lenders

Document classification is a crucial initial step in the lending process that helps lenders identify, categorize and extract relevant information from various documents submitted by applicants.
This process can be time-consuming, error-prone and resource-intensive. When done manually, it requires lenders to sift through hundreds or even thousands of pages of documents, which can lead to mistakes and delays in the lending process.
However, automation solutions, such as machine learning-based document classification algorithms, can significantly reduce the time and effort needed to classify and extract data from documents. For example, ForwardLine Financial reduced loan approval time from three hours to under 45 minutes by leveraging intelligent document processing.
What is document classification?
Document classification is the process of categorizing and organizing documents based on their content, type, or other predefined criteria. It involves analyzing the textual or visual information present in a document and assigning it to a specific category or class.
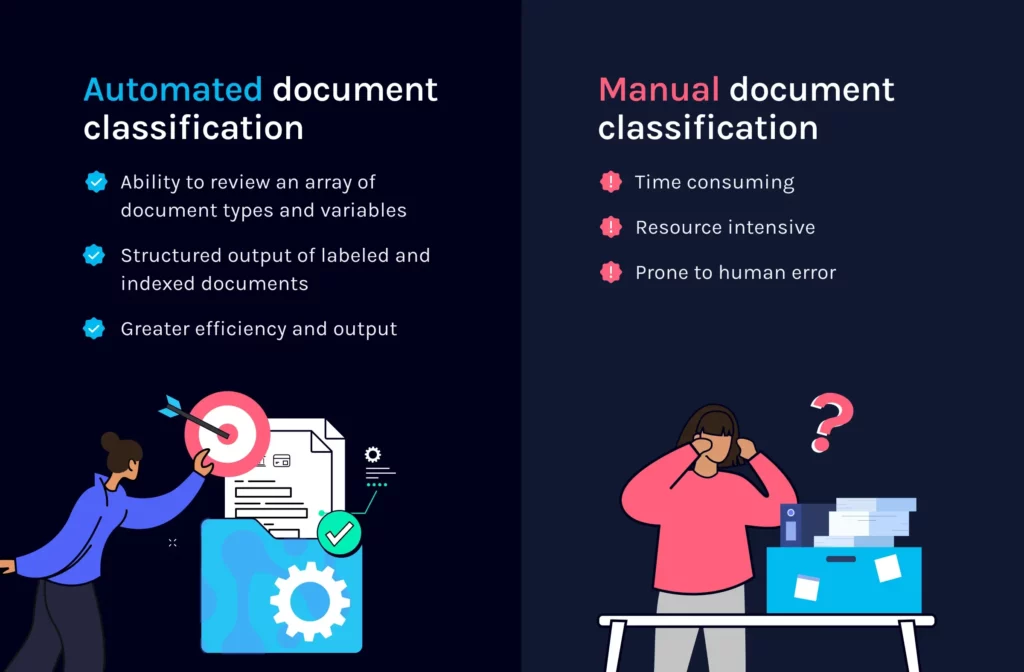
Manual vs Automated Document Classification
Manual document classification typically requires a lender to review each document submitted by an applicant individually to assess its content and determine its category. This involves reading through the document to understand its context, labeling the document and sorting it into the appropriate category. When done manually, this process can be time-consuming and prone to errors, especially when dealing with a large volume of documents.
On the other hand, automated document classification utilizes technology such as machine learning algorithms to automate and streamline this process. By training a model on a labeled dataset, the algorithm can learn patterns and features from the documents and predict their categories. This eliminates the need for manual intervention and speeds up the classification process.
By automating document classification, lenders can accelerate the lending process, enhance productivity and ensure consistent and reliable categorization of documents. This frees up lenders to focus more on analyzing the extracted data and making informed lending decisions rather than spending excessive time assessing and organizing documents.
3 Key Benefits of Automated Document Classification with Machine Learning
Automated document classification offers several advantages over the manual approach – especially when powered by machine learning and a continuously growing set of training data.
Not only does automation enable lenders to reduce the time and effort required to classify documents and eliminate human errors, intelligent document processing can help improve overall operational efficiency by enabling businesses to generate strategic insights from their data.
Some of the key benefits of automating classification with AI-powered document automation systems include:
Ability to review an array of document types and variables
Automation solutions for document classification can handle various document formats, including parseable PDFs, scans, smartphone images and more. Machine learning algorithms are designed to be highly adaptable and can accurately process and classify diverse document types, surpassing human capabilities in accuracy and versatility.
Structured output of labeled and indexed documents
Automated document classification systems provide a structured data output, labeling each document with its appropriate category or class. This structured output enables lenders to quickly identify incorrectly submitted or missing information and promptly notify borrowers, reducing the back-and-forth communication and speeding up the document collection process.
Greater efficiency and output
Automation solutions leverage machine learning algorithms to process documents at a higher speed and larger scale compared to manual methods. This increased efficiency enables lenders to handle a higher volume of loan applications without compromising accuracy. By efficiently classifying and routing documents, automation contributes to smoother downstream processes, such as data extraction, verification and underwriting.
Automated Document Classification Use Cases
Automated document classification provides valuable benefits across various types of lending, including mortgage, small business (SMB) lending, consumer lending and more. Each of these requires borrowers to submit a wide range of documents, and automated classification helps each type of lender quickly and accurately categorize them for more efficient review, analysis and underwriting. Some key use cases for automated document classification technology include:
Mortgage Lending
- Income statements
- Tax returns
- Bank statements
- Property-related documents
SMB Lending
- Financial statements
- Balance sheets
- Income statements
- Other business-related documents
Consumer Lending
Compliance and Risk Management
In addition to accelerating the lending process, automated document classification can help lenders comply with regulatory requirements and assess risks associated with lending. By automating the classification of applicant documents, lenders can ensure adherence to regulations, reduce the risk of fraud and streamline compliance processes.
How does automated document classification with Ocrolus work?
Ocrolus is an automated document classification solution that leverages advanced machine learning and data extraction techniques to streamline the document processing and classification for lenders. Our three-step process ensures accurate document classification and structured data output.
Auto Classify Documents with Precision
Ocrolus utilizes machine learning algorithms trained on large datasets to automatically classify and categorize documents. These algorithms can handle various document types, including bank statements, pay stubs, tax returns and more. With high precision, Ocrolus accurately identifies the document type, allowing lenders to quickly organize and process large volumes of documents.Human-in-the-Loop Validation, Including Data Labeling and Quality Control
Ocrolus combines the power of automation with human validation to ensure the highest level of accuracy. The system presents any classified documents with imperfect confidence to human reviewers for validation and quality control. These reviewers verify the accuracy of the document classification, label any missing data points and ensure the overall quality of the extracted information. This human-in-the-loop validation process helps improve the accuracy of the automated classification and enhances data integrity.Structured and Clean Data Output
Once the document classification and validation process is complete, Ocrolus provides structured and clean data output. The solution extracts relevant data points from the documents, such as transaction details, income figures, borrower information and more. The data is organized in a standardized format, making it easily readable and compatible with downstream systems. Lenders can access the extracted data in a structured manner, enabling them to efficiently analyze and make informed decisions.
Ocrolus’ “human-in-the-loop” verification process enables lenders to automate the document classification and data extraction process with confidence. Through a combination of machine learning and human intelligence, lenders are empowered to save significant time and resources while improving the speed, efficiency and accuracy of their document processing and lending workflows.
Serving as the basis for lenders’ decisions, document classification plays a crucial role in the lending process.
When performed manually, this process can be tedious and time consuming. But by automating document classification with intelligent automation technology like Ocrolus, lenders are empowered to streamline operations and deliver an improved customer experience while making faster and more accurate lending decisions
Book your demo to discover how Ocrolus’ helps lenders accelerate document classification and make high quality decisions with AI-driven document automation.

