The inference layer: Engineering predictable AI for production lending

TL;DR: In lending, inference is where AI creates value, not in training. The inference layer is the key part of the production stack that turns messy documents and data into structured, audit-ready outputs with predictable latency and unit economics. Ocrolus leverages frontier models but largely runs core workflows on specialized language models tuned for lending, effectively managing hardware and infrastructure volatility so teams can scale without re-architecting.
Co-authored with Flaviu Andreescu
In mortgage and small-business lending, AI only matters if it works predictably in production. Turnaround times are commitments, accuracy is regulated and scale is non-negotiable. For CIOs and CTOs, the goal isn’t to manage runtime inference, infrastructure or training models. It’s to make confident lending decisions with assurance that the platform underneath will perform as volume and complexity increase.
Inference is the runtime stage of machine learning in which models run on live inputs, such as bank statements, pay stubs or tax forms, to produce outputs that a system can use. The inference layer is the production stack that makes high-volume, real-time processing possible at scale. It is the orchestration, computation and validation environment between raw document data and the underwriting systems that depend on structured data.
If this layer isn’t engineered for production discipline, AI remains a high-cost experiment. When engineered correctly, it becomes a predictable engine for growth.
That is the posture Ocrolus takes. Ocrolus is an AI-powered workflow and data analytics platform that transforms messy financial documents and digital data into regulatory-grade decision intelligence. The platform absorbs the complexity of inference management so lenders don’t have to. They can rely on a scalable AI foundation that improves over time, remains transparent and auditable and avoids the black-box problem.
From frontier models to specialized intelligence
Ocrolus actively leverages, evaluates and benchmarks the best off-the-shelf large language models available, including the latest releases from Anthropic, Google (Gemini) and OpenAI. These models set the frontier for general reasoning and language understanding. Ocrolus uses these as continuous reference points to ensure the platform reflects state-of-the-art capability.
At the same time, Ocrolus does not run core lending workflows directly on the general-purpose foundation models. Instead, it operates a portfolio of specialized language models (SLMs), distilled from frontier open-source LLMs and tuned on proprietary financial document data across lending use cases such as mortgage and SMB lending. Focusing on the KPIs that matter most in production lending: accuracy, latency and cost, these SLMs consistently outperform general-purpose LLMs for Ocrolus core lending workflows.
The reason is focus. These models are engineered to do a specific class of financial work extremely well: producing structured, reproducible and auditable outputs from complex documents at scale.
Why lenders shouldn’t have to care about inference
In real lending environments, AI in operations is largely delivered via inference. Documents arrive continuously, volumes fluctuate and performance expectations are always rising. Many platforms expose this complexity to customers, forcing them to consider throughput limits, cost tradeoffs, model selection, hardware families and more.
Ocrolus deliberately hides that complexity. Inference efficiency, scaling behavior and cost discipline are handled by the platform. A lender doesn’t need to know how many floating-point 16 operations an L40S chip can perform per second or whether speed improvements in NVIDIA Blackwell offset costs relative to the Hopper architecture. Instead, Ocrolus manages this so lenders experience consistent latency, predictable outcomes and the ability to expand automation without worrying about what happens under the hood.
Engineering for scale without making it your problem
Behind the scenes, Ocrolus continuously tunes its inference infrastructure with real mortgage and SMB workloads. As usage patterns evolve across document types, customer segments and automation paths, the system adapts. Capacity expands and contracts as needed, ensuring stable performance without excess cost.
At a deeper level, the platform is optimized with a hardware-aware approach to inference. Execution paths are designed to align with how modern accelerators operate, maximizing throughput per unit of compute. Ocrolus routinely audits and updates its fleet of accelerators to sustain performance across the mix of math operations present in evolving model architectures. This improves latency efficiency while strengthening the customer experience. The complexity stays inside the platform. The benefits show up in speed, reliability and scale.
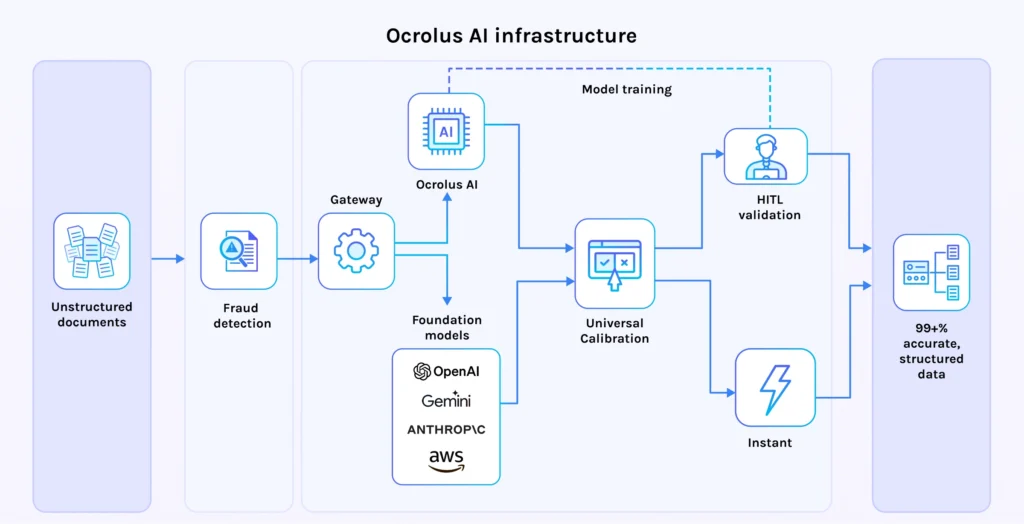
Extending into agents and analytics with explainability intact
The same inference discipline extends beyond individual model calls. In Ocrolus agentic workflows and analytics, multiple specialized models coordinate across a single lending flow, reasoning across documents and assembling higher-order insights to generate validated decisions.
These workflows introduce more sophistication without opacity. Every oƒutput remains traceable to source documents and underlying data. Calculations are inspectable. Decisions are explainable. Whether the result comes from a single model or a multi-step agentic process, the system is designed to support regulatory review, investor diligence and internal quality control.
Ocrolus has intentionally designed its platform to avoid the black-box problem many AI companies face. It is a system optimized for performance while preserving visibility and trust.
Confidence, not configuration
For CIOs and CTOs, the value of AI in lending requires confidence that the platform will scale as volumes grow, that decisions are defensible and auditable and that the technology will continue to improve without forcing constant architectural change or operational burden onto their teams.
Ocrolus delivers that confidence by combining continuous benchmarking against the best frontier models with purpose-built systems that outperform on key lending metrics. The platform absorbs the complexity of model selection, inference optimization and infrastructure evolution so lenders can focus on policy, risk and growth.
Ocrolus is not positioning AI as a thin layer on top of lending workflows. It is engineering AI as core infrastructure built on specialized language models, a hardware-aware inference layer, scalable agentic systems and analytics designed for traceability and trust.
The inference layer is where this philosophy becomes tangible. It’s what allows Ocrolus to deliver best-in-class latency, cost efficiency and accuracy while keeping the system transparent and dependable for the lenders who rely on it every day.
Key takeaways
- In lending, inference is the runtime stage where AI creates value, and the inference layer determines whether that value is predictable in production.
- The inference layer is the orchestration, computation and validation environment between raw document data and underwriting systems that depend on structured outputs.
- Frontier models are useful reference points, but specialized language models are often a better fit for core, regulated, document-heavy lending workflows.
- A production-grade inference layer absorbs hardware and infrastructure volatility to preserve predictable latency and unit economics as volumes scale.
- Audit readiness requires traceability, inspectable calculations and reproducible outputs, not black-box automation.

