AI-native vs. AI-enabled vendor partners: why it matters for lenders

TL;DR: AI-native and AI-enabled are not interchangeable terms. AI-native platforms like Ocrolus are built from the ground up on purpose-built models, domain-specific training data and production infrastructure engineered for lending workflows — and have been since before generative AI went mainstream. AI-enabled platforms incorporate AI into existing systems. The distinction affects accuracy on complex borrower profiles, reliability at scale and the capacity to support agentic underwriting workflows.
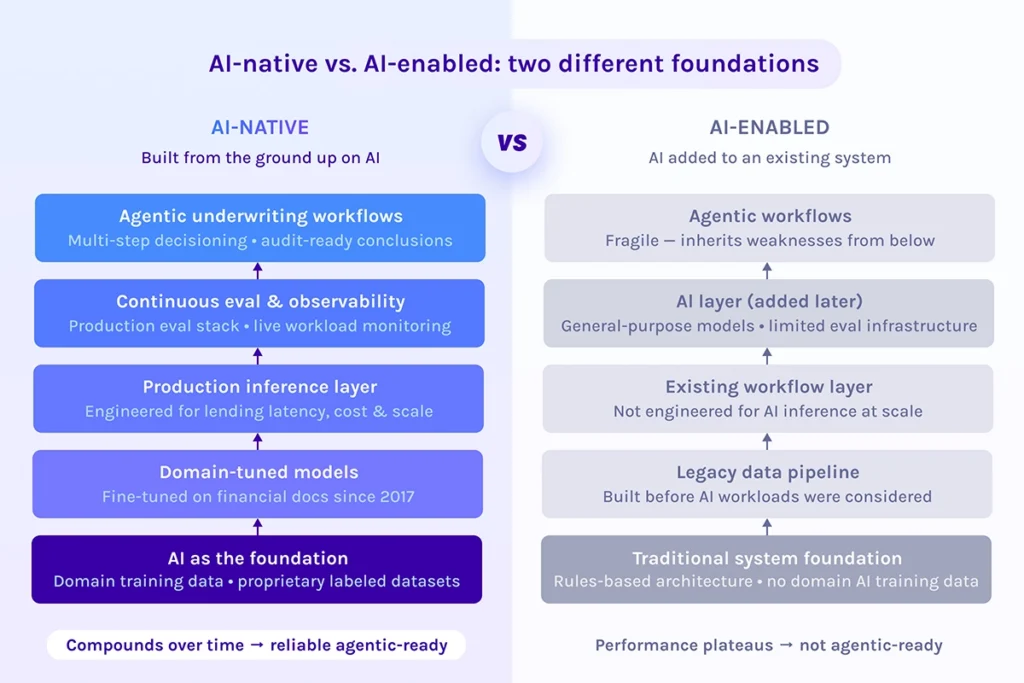
Every major lending technology vendor now claims AI. The label appears in pitch decks, product pages and trade show booths with enough regularity that it has stopped meaning anything. For lenders evaluating technology, the useful question is not whether a vendor uses AI — it’s when AI became foundational to the platform’s architecture and what has compounded since.
There is a meaningful difference between AI-native and AI-enabled technology. AI-native platforms are built from the ground up on purpose-built models, domain-specific training data and production infrastructure designed specifically for AI workloads. AI-enabled platforms are traditional systems that have incorporated AI capabilities over time. Both may perform adequately on standard cases. The gap opens on the ones that aren’t standard.
The compounding advantage of building AI first
AI-native infrastructure compounds in a way that AI-enabled systems cannot replicate on a short timeline. A platform that has been training purpose-built models on financial documents since 2017 has absorbed years of edge cases, unusual document formats, failure modes and correction cycles that a newer AI adopter simply hasn’t encountered yet. That gap doesn’t close quickly — it widens, because the training flywheel keeps spinning with every application processed.
The mechanics of this advantage are worth understanding. Fine-tuned models trained on domain-specific financial data consistently outperform general-purpose language models on lending tasks because they internalize the document structures, numeric conventions and layout variability that define real-world underwriting. A general-purpose model can handle a clean W-2. A model trained on millions of financial documents — including the handwritten, photographed and non-standard ones — handles the edge cases that drive manual review and escalations.
The same principle applies at the infrastructure level. A production inference layer engineered specifically for lending workflows — managing latency, cost and accuracy across high document volumes — behaves differently under load than AI capabilities added on top of legacy infrastructure. Purpose-built doesn’t just mean more accurate. It means more predictable at scale.

Ocrolus was incorporating AI into its platform a decade over, well before the mainstream AI wave.
Where the gap appears for borrowers
The compounding advantage surfaces where it matters most: in how lenders serve the people borrowing from them. AI-native infrastructure handles the messy slice of the portfolio that defines real-world underwriting — self-employed borrowers, mixed income streams, non-standard document formats and multi-entity business structures. That’s where accuracy matters most, where manual review concentrates and where delays in decisions are felt most acutely by applicants.
For lenders, this translates into measurable outcomes. More accurate income calculations across complex borrower types mean fewer conditions are generated unnecessarily. Fewer conditions mean faster closings. Faster closings mean applicants get answers when it matters, not after a week of back-and-forth. An AI-enabled vendor may quote comparable accuracy on a standard document set. The difference appears on the documents that don’t cooperate or are perfectly templated.
Sustaining that accuracy at scale requires more than good models — it requires continuous evaluation and monitoring against real lending workloads. A platform that has been running an eval stack against live production data for years has learned what “good” looks like across the full range of borrower profiles, not just the clean ones.
Why AI-native infrastructure is the prerequisite for what comes next
The lending industry is moving toward agentic underwriting: AI systems that orchestrate multi-step decisioning workflows with minimal human intervention, reasoning across documents, applying policy and producing audit-ready conclusions. That trajectory requires AI-native infrastructure as its foundation.
Layering agentic workflows on top of AI-enabled architecture compounds the fragility underneath. If the models feeding an agent are general-purpose, if the inference layer isn’t engineered for production lending and if there’s no continuous eval system verifying accuracy, the agent inherits those weaknesses and amplifies them across every decision step. The output becomes harder to audit, not easier.
Vendors positioned to deliver reliable agentic underwriting are the ones who have already built the foundation layer by layer. As we’ve covered in depth, what a real lending AI stack looks like includes purpose-built models, a production inference architecture, continuous evaluation and governed human-in-the-loop processes. Agentic capabilities built on that foundation can extend naturally, with traceability intact.
The right question for any vendor evaluation isn’t “do you use AI?” It’s “when did AI become foundational to your architecture, what has the system trained on and what has the improvement curve looked like since?” The answer reveals whether you’re looking at a platform that has been compounding domain intelligence for years or one that incorporated AI capabilities into what was already there. For lenders, that distinction matters operationally today — in accuracy, reliability and the pace of manual review. And it determines what the platform is capable of becoming.
Key takeaways
- “AI-powered” has become a table-stakes marketing claim. The meaningful differentiator is whether AI is foundational to the platform’s architecture or layered onto an existing system.
- AI-native infrastructure compounds: years of domain-specific training data, model iterations and failure-mode corrections create an advantage that newer AI adopters cannot close quickly.
- The compounding advantage shows up in outcomes lenders and borrowers care about — accuracy on complex profiles, fewer unnecessary conditions and faster decisions.
- Sustaining accuracy at production scale requires continuous evaluation against real workloads, not just strong models at launch.
- AI-native infrastructure is the prerequisite for reliable agentic underwriting. Agents built on fragile foundations inherit and amplify that fragility across every decision step.
FAQs
What is the difference between AI-native and AI-enabled lending technology?
AI-native platforms are built from the ground up on purpose-built models, domain-specific training data and production infrastructure engineered for AI workloads. AI-enabled platforms are traditional systems that have added AI capabilities over time. The distinction matters in practice: AI-native infrastructure compounds over years of domain training and iteration, while AI-enabled systems tend to perform well on standard cases but show gaps on the edge cases that define real-world lending portfolios.
Why does AI-native infrastructure produce better accuracy on complex borrower profiles?
General-purpose AI models are trained on broad data and perform well on clean, structured inputs. Financial documents in lending — particularly those from self-employed borrowers, multi-entity businesses and non-standard formats — require models that have been trained specifically on that document type and its real-world variation. Purpose-built, fine-tuned models absorb the edge cases, layout variability and numeric conventions that general models miss, which is what produces consistent accuracy on the hard slice of the portfolio.
How long has Ocrolus been building AI-native lending technology?
Ocrolus has been building on AI since 2017, including the use of large language model technologies before generative AI became mainstream. The platform’s core architecture — purpose-built models, a production inference layer and a continuous evaluation system — was designed with AI as its foundation, not added to an existing product later. That timeline represents years of compounding training data, model refinement and production learning across hundreds of thousands of credit applications processed monthly.
What is agentic underwriting and why does AI-native infrastructure matter for it?
Agentic underwriting refers to AI systems that can orchestrate multi-step decisioning workflows — reasoning across documents, applying lender policy and producing audit-ready conclusions — with minimal human intervention. Reliable agentic workflows require the underlying AI infrastructure to be production-grade: purpose-built models that handle complex documents accurately, an inference layer that performs predictably at scale and a continuous eval system that validates output quality. AI-enabled architecture, where AI is layered on top of legacy systems, introduces fragility that agents inherit and amplify across every step of the workflow.

